Are many useStates better than useState(object)?
Lately I've converted a lot of class components to functional. One question left me curious every time — why do I feel like splitting the old class state into so many useState(atom) — one for each state key? Is there any real benefit in it? Should I just leave a single useState(whatever this.state was) to touch as little code as possible during refactoring? Today, we'll discuss if having many useState(atom) is better than one single useState(object) — and, exactly, why. (Spoiler: it depends).
Collection => object state
To get the obvious out of the way: if your state is a collection — multiple similar values, probably dynamic quantity, normally in an array or a key:value object — you have to use object state. Someone with a dirty mind could work around that with serialization or recursive components, but let's not go there.
State decomposition
Common architectural sense tells us to split totally unrelated pieces of state into multiple useStates. The ability of separating state like that is one of the better features hooks offer. If you have a component that tracks input value, but also happens to track wheter the input has focus, go ahead and separate focus-state and value-state:
// no
const [{ value, isFocused }, setState] = useState({
isFocused: false,
value: '',
});
return <input
value={state.value}
data-focus={isFocused}
onChange={e => setState({ value: e.target.value, isFocused })}
onFocus={() => setState({ value, isFocused: true })}
onBlur={() => setState({ value, isFocused: false })}
/>
// yes
const [isFocused, setFocused] = useState(false);
const [value, setValue] = useState('');
return <input
value={value}
data-focus={isFocused}
onChange={e => setValue(e.target.value)}
onFocus={() => setFocused(true)}
onBlur={() => setFocused(false)}
/>I'm getting a bit ahead of myself, but the second variant is shorter and looks clearer to me. You also get to use the extra convenience useState provides for atomic values (more on that in a moment). Also, if at some point you decide to extract focus-management into a custom hook, you're well prepared.
— But wait, Vladimir, didn't you just tell us to wrap context value in an object, even if it has a single item?
— Yes, but this time it's different! To change context value from atom to an object, you must edit all the places where you read the context — that's your whole codebase. Component state is local, so it takes a single destructuring — [value, setValue] = useState(0) -> [{ value }, setValue] = useState({ value: 0 }). Besides, unlike context, state shape is not likely to be your public API.
useState(atom) benefits
Now let's see, exactly, why useState works better with atomic values.
Convention
The feeling that useState should be used with atoms is there for a reason — the API is designed to push you towards this idea.
First, setState({ value: 0 }) sets the state to that exact object — { 'value': 0 }. Class component's this.setState({ value: 0 }) will merge the update with the current state. You can mimic this behavior with a spread: setState({ ...state, value: 0 }), but note how you're fighting react. Manually constructing the next state object without spreads: setState({ focus, value: 0 }) is explosive — it's easy to miss an update site if you're adding a new key to your state and erase a part of the state.
Next, as explained in my post on useState tricks, setState(value) does nothing when value is equal to the current state. Working with atomic values makes it trivial to use this feature, because atoms are compared by value. By contrast, this.setState({ value }) in a PureComponent is followed by a shallow object equality check.
So, while class components were designed to work best with objects (indeed, component state is always an object), useState has a speacial optimization for atomic values, and does includes no conveniences for working with objects. You can work around both issues with a custom hook, but why fight React if it politely asks you to prefer atomic state?
Bundle size
One possible advantage of not using objects is the reduced bundle size — the original hooks announcement by React team specifiaclly mentioned that classes don’t minify very well. Let's pass our sample component that tracks focus and value through the normal build toolchain — babel + terser + gzip, and see if that's true.
Looking at the minified object-state variant, we can see that the minifier can't do anything about the keys of our object. Terser is very smart, but it has no idea if isFocused and value keys mean anything to that useState function we're passing our object through, so it can't mangle the keys. Note, however, that this has nothing to do with classes — any object has the same problem. Here's the component — It's 338 bytes raw, and 128 bytes under gzip:
function(){var t=e(useState({isFocused:!1,value:""}),2),n=t[0],r=n.value,o=n.isFocused,u=t[1];return React.createElement("input",{value:state.value,"data-focus":o,onChange:function(e){return u({value:e.target.value,isFocused:o})},onFocus:function(){return u({value:r,isFocused:!0})},onBlur:function(){return u({value:r,isFocused:!1})}})}}Now let's try the object-free version. It doesn't pass the state object anywhere, and symbolic variable names are successfully mangled:
function(){var t=e(useState(!1),2),n=t[0],r=t[1],o=e(useState(""),2),u=o[0],i=o[1];return React.createElement("input",{value:u,"data-focus":n,onChange:function(e){return i(e.target.value)},onFocus:function(){return r(!0)},onBlur:function(){return r(!1)}})}}This minified component is 273 bytes. So, case solved — at 65 bytes, or 20% off, atoms win, objects suck, right? Not so fast: the gzip size is 112 bytes, only 16 bytes / 12.5% smaller, and that's an abyssmal difference, especially in absolute terms.
In case you're curious, I included React in both bundles to gize gzip some warm-up data. I also transpiled down to IE11. Have fun with your own measurements if you feel I missed something!
So, you'd have to try very hard, with hundreds of components, to get any meaningful post-gzip bundle size reduction from using atomic state over objects. Still, the difference exists, so that's half a point to atoms.
Should you ever useState(object)?
So far, we've seen that multiple useState(atom) work well for breaking state into independent fragments. Atomic state is often more convenient, more conventional and gives you a slightly smaller bundle. So, are there any reasons to use object state in hooks, other than managing collections? There is a couple.
Update batching
As we've discussed before, React <18 will not batch state updates from outside event handlers. Let's look at a familiar data-fetch example:
const Hints = () => {
const [isLoading, setLoading] = useState(true);
const [hints, setHints] = useState([]);
useEffect(async () => {
fetch('/hints')
.then(res => res.json())
.then(data => {
setHints(data);
setLoading(false);
});
}, []);
return <>
{isLoading
? 'loading...' :
hints.map(h => <span>{h}</span>)}
</>
};The component mounts with a loading indicator, calls an API endpoint, then disables the loader and shows some data once loaded. The only problem here is that since loading and hints are set via 2 different state updates from a promise (that's not an event handler), you end up rendering and modifying the DOM twice after load.
Grouping the loading flag and data into an object allows us to update the state in one call, eliminating the extra render:
const [{ isLoading, hints }, setSuggest] = useState({
isLoading: true,
hints: [],
});
useEffect(() => {
fetch('/hints')
.then(res => res.json())
.then(data => {
setSuggest({
hints: data,
isLoading: false,
});
});
}, []);Granted, you can also work around this issue while keeping your state split with a scary-sounding unstable_batchedUpdates from react-dom:
const [isLoading, setLoading] = useState(true);
const [hints, setHints] = useState([]);
useEffect(() => {
fetch('/hints')
.then(res => res.json())
.then(data => {
// triggers just one render
unstable_batchedUpdates(() => {
setHints(data);
setLoading(false);
});
});
}, []);Still, I'd prefer grouping state in an object over using unstable_ things and trying not to forget it every time I update the state. That's one use case where wrapping related state in an object makes sense — until react 18, it produces fewer renders when updating these related values.
Arrow updates
If you recall, useState allows you to update state using a callback AKA mini-reducer. The callback gets the current value as an agrument. We can use it to avoid data fetch race condition in a typeahead:
const Hints = () => {
const [search, setSearch] = useState({
query: '',
hints: [],
});
useEffect(() => {
fetch(`/hints/${search.query}`)
.then(res => res.json())
.then(hints => {
setSearch(s => {
if (s.query !== search.query) {
// skip the update if query has changed
return s;
}
return { ...search, hints }
})
});
}, [search.query]);
return <>
<input
value={state.query}
onChange={e => setSearch({ ...search, query: e.target.value })}
/>
{state.hints.map(h => <span>{h}</span>)}
</>
};Here, we look at the current query after loading the hints, and only show the hints we loaded if the query has not changed since. Not the most elegant solution, but it works, and so it's a valid state model. If you were to split query and hints into separate states, you'd lose the ability to read current query when setting hints, and have to solve this problem some other way.
More generally (maybe too generally), if updates to state B depend on state A, states A and B should probably we wrapped in an object.
Appendix A: useObjectState
I promised you can have all the convenience of class setState in a custom hook. Here we go:
function useObjectState(init) {
return useReducer((s, patch) => {
const changed = Object.entries(patch)
.some(([k, v]) => s[k] !== v);
return changed ? { ...s, ...patch } : s;
}, init);
}Here, we merge old and new state, and also preserve the old state object reference if the patch contains no changes. Easy breezy.
Appendix B: Runtime performance
For a tie-breaker, let's see if the amount of useState calls impacts your application performance.
I expect the runtime performance difference between single object state and multiple atomic states to be even more negligible than that of bundle size. Still, the fact that it could go both ways is made me curious: object state allocates an extra object (or function, with a lazy initializer) on every render, but atoms call more react internals. Is there a winner?
I've made a tiny benchmark comparing several useState calls, single useState(object) call and single useState(() => lazy object). The results are available in a google sheet. I've also made a nice chart that shows percent increase in mount time over baseline — no hooks, just a stateless render:
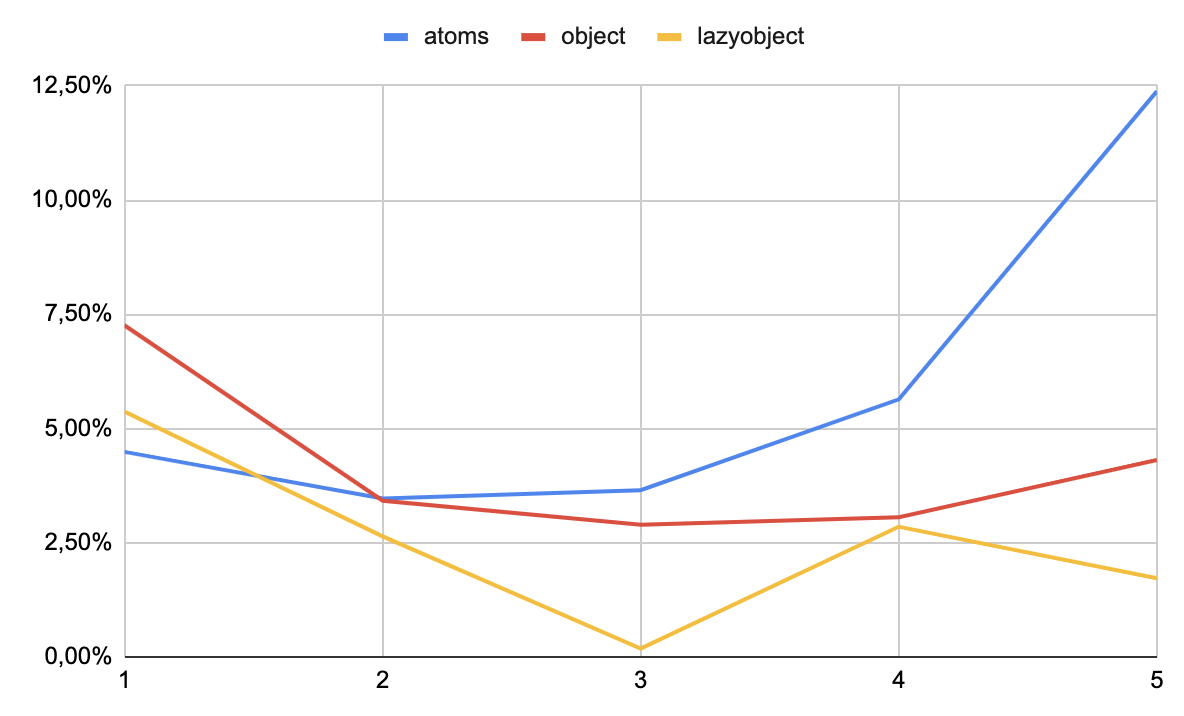
I wouldn't dare interpret these results given how cool optimizing compilers are, but the general as I see it pattern makes sense:
- 1
useStatewith atom is slightly better than with object because we skip object allocation. useStatecalls are more expensive than object allocations, so for 3+ itemsuseState(object)wins.- Lazy initializer beats object creation — not sure why, if the initializer is always called on mount.
Note that the difference here is in sub-microsecond range (yes, MICROsecond, 1/1000th of a millisecond, or 1/16000th of a 60FPS frame), so any practical implications are laughable. Still, good to know that using hooks is almost free.
So, useState is probably better suited for storing atomic values, but object state still has its uses. Here's what we learnt:
useStateupdate handle skips re-render by checking for===equality, and that's easier to achieve with atomic values.useStatehas no built-in object merging mechanism.- Atomic state makes your bundle a little bit smaller, because object keys are hard to mangle.
- Collection state only works as an object.
- Until React 18, async updates to several
useStatesresult in useless renders. Use object state orunstable_batchedUpdatesto render once. - You can't access the current state of another
useStatein a state update callback (ouch, that's a complex statement with many states involved) — use object state for values that depend on each other during update. - Any performace difference between
useStatevariants is negligible.
I feel the deciding factor here is state modelling — grouping several state items in an object signals that they are closely related, while splitting them apart shows they are orthogonal. Please model your state based on common sense, not some prejudices agains objects. Ah, and also — everything we just discussed also applies to useReducer, because useState is useReducer. Good luck and see you next time!
